02 블랙보드 게시글 가져와서 출력하기: Selenium 기반 크롤링 엔진 제작
게시글 링크
- 01 개발 준비: Selenium / Requests 개발환경 세팅하기
- 02 블랙보드 게시글 가져와서 출력하기: Selenium 기반 크롤링 엔진 제작
- 02-1 블랙보드 게시글 가져와서 출력하기: Requests, Session 기반 크롤링 엔진 제작
- 03 블랙보드 신규 글 확인하기: MySQL 데이터베이스 연동
- 04 블랙보드 신규 글 알림 기능 제공하기: SMTP 메일링 기능 추가
- 05 정기적으로 작동하게 만들기: Scheduling 기능 추가
- 여태까지 최종 결과물 소스코드 레포
- 06 블랙보드 알림 안드로이드 어플리케이션 만들기: 크롤링 엔진을 Django Rest Framework API 서버로 수정, 서버에 Deploy
- 07 블랙보드 알림 안드로이드 어플리케이션 만들기: Android 앱 개발, API 서버와의 연동
- 07-1 블랙보드 알림 챗봇 서비스 만들기: 카카오톡 챗봇 개발, API 서버와의 연동
- 블랙보드 알림 안드로이드 어플리케이션 결과물 레포
- 블랙보드 알림 챗봇 서비스 결과물 레포
- 블랙보드 알림 API 서버 결과물 레포
블랙보드 로그인 구현
- 이제 실제 프로젝트 코드를 작성해봅시다!
- 블랙보드 사이트에 로그인을 진행할건데, 간단하니 함께 따라와주세요:)
- 우선 블랙보드에 들어가볼게요. (https://kulms.korea.ac.kr)
- 이제 우리는 크롤링을 할 때 가장 많이 쓰는 툴인 크롬
개발자도구를 써보겠습니다. - 크롬 개발자도구를 다음과 같이 키면 이런 화면이 나옵니다!
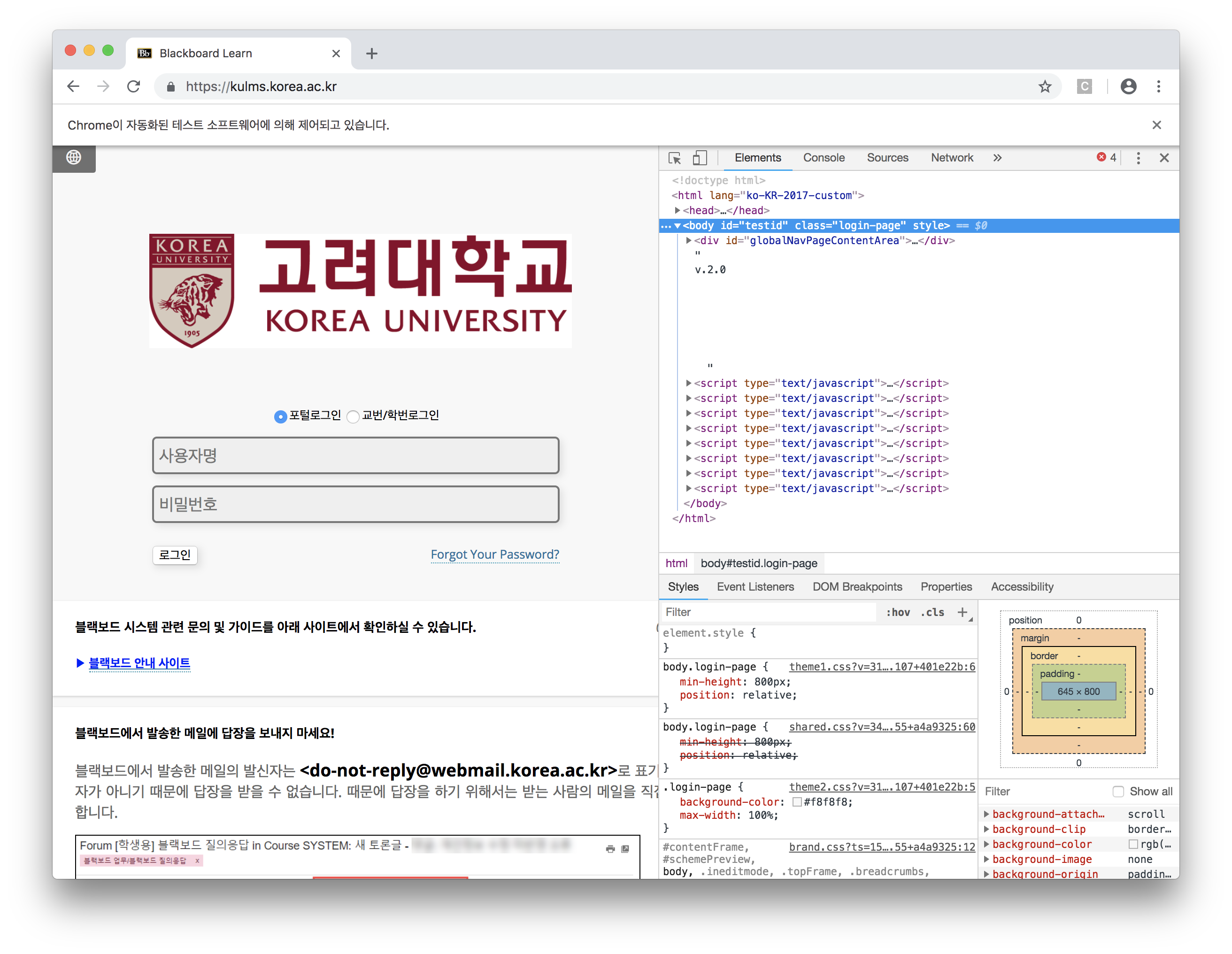
- 이 화면에서 왼쪽 상단의 커서를 통해 내가 원하는 웹 구성 요소에 대한 정보를 얻을 수 있습니다.
- 로그인을 하려면 id, password를 각각 입력하고 로그인 버튼을 눌러야겠죠?
- 그러면 id 입력 창을 찾아보겠습니다.
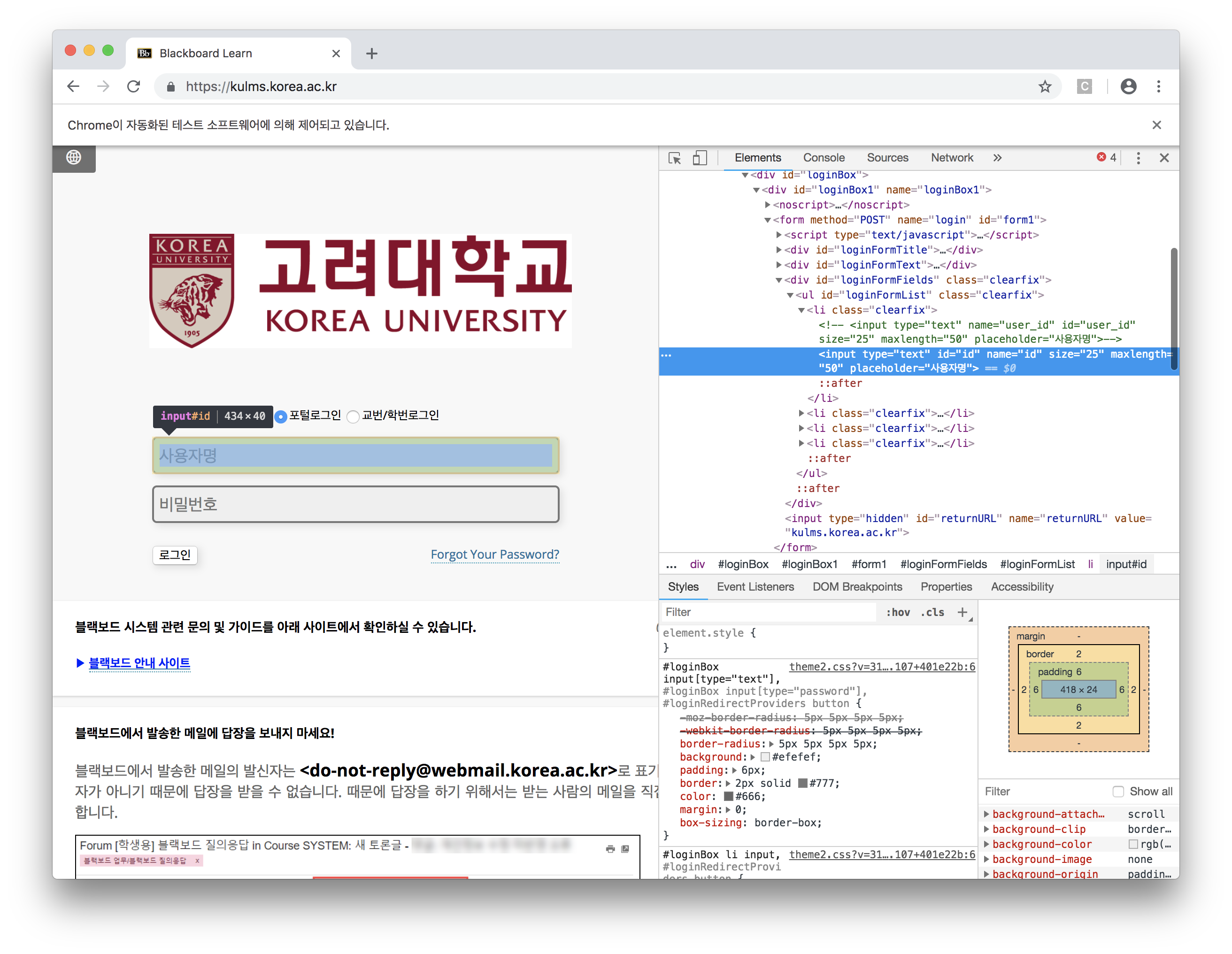
- 이렇게 보시면 input 태그의 id 입력창이 나오는데, 여기
name = "id"보이시죠? 이걸 활용합니다. - 그럼 이제 파이썬으로 돌아와서 다음과 같이 코드를 작성해볼게요.
…/BlackBoard-Tutorial/crawl-demo.py
1 | driver.find_element_by_name('id').send_keys('YOUR_BLACKBOARD_ID') # id 입력하기 |
- 위의 코드는 name이 id인 element를 찾아 내가 원하는 string을 입력하도록 하는 코드입니다. 내 블랙보드 아이디를 쓰면 되겠죠?
- 비밀번호도 마찬가지로 진행합니다.
- 이제 로그인 버튼을 눌러야 하는데, 로그인 버튼을 찾아서, 오른쪽 마우스 -> copy -> copy by xpath를 눌러 복사합니다.
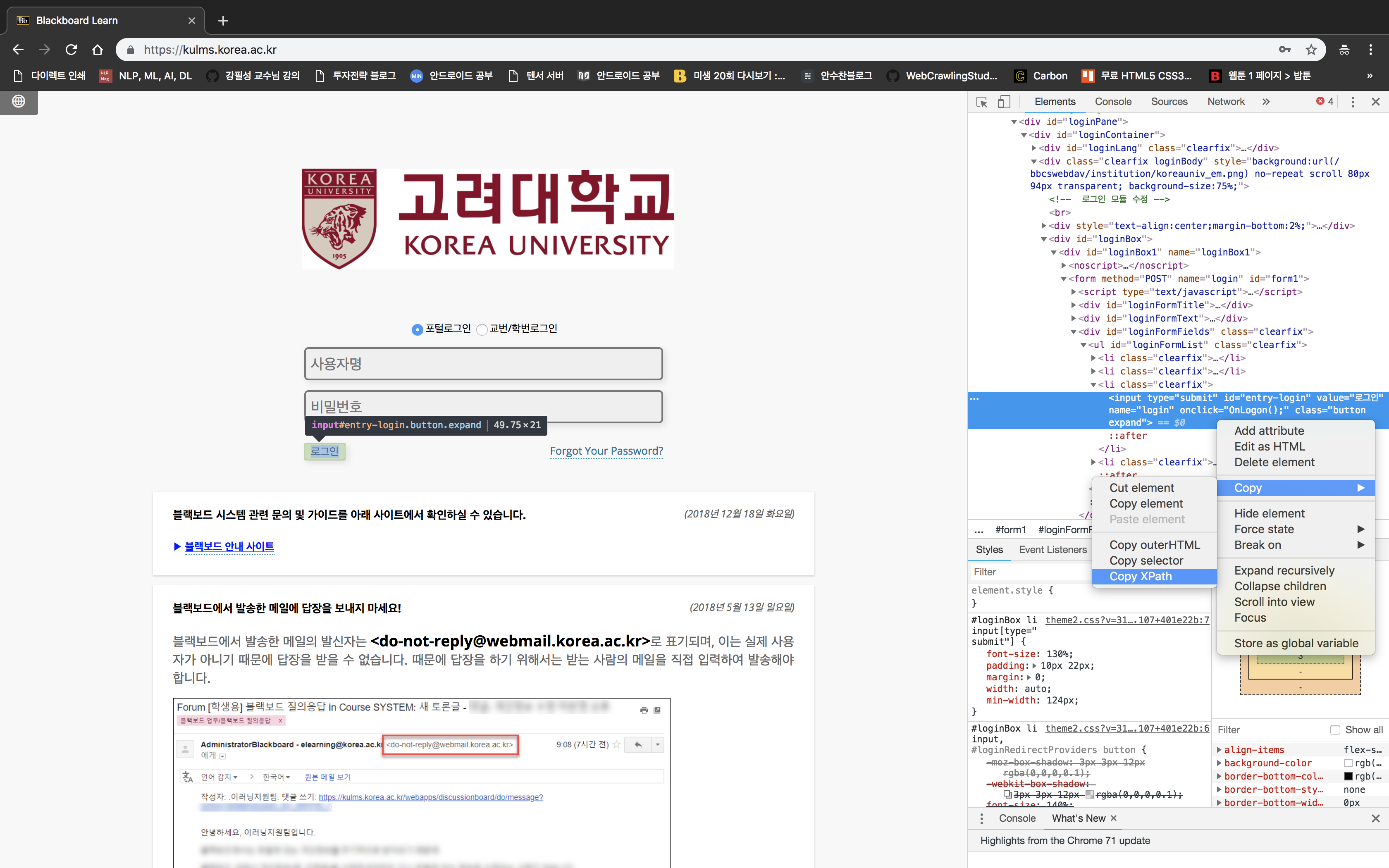
- 코드는 이렇게 씁니다.
…/BlackBoard-Tutorial/crawl-demo.py
1 | driver.find_element_by_xpath('//*[@id="entry-login"]').click() # 로그인 버튼 클릭 |
- 위 코드를 통해 버튼 클릭을 실행시킬 수 있습니다.
- 여기까지의 전체 코드는 다음과 같아요!
…/BlackBoard-Tutorial/crawl-demo.py
1 | from selenium import webdriver |
- 실행시키면 로그인이 원활하게 되는걸 볼 수 있어요:)
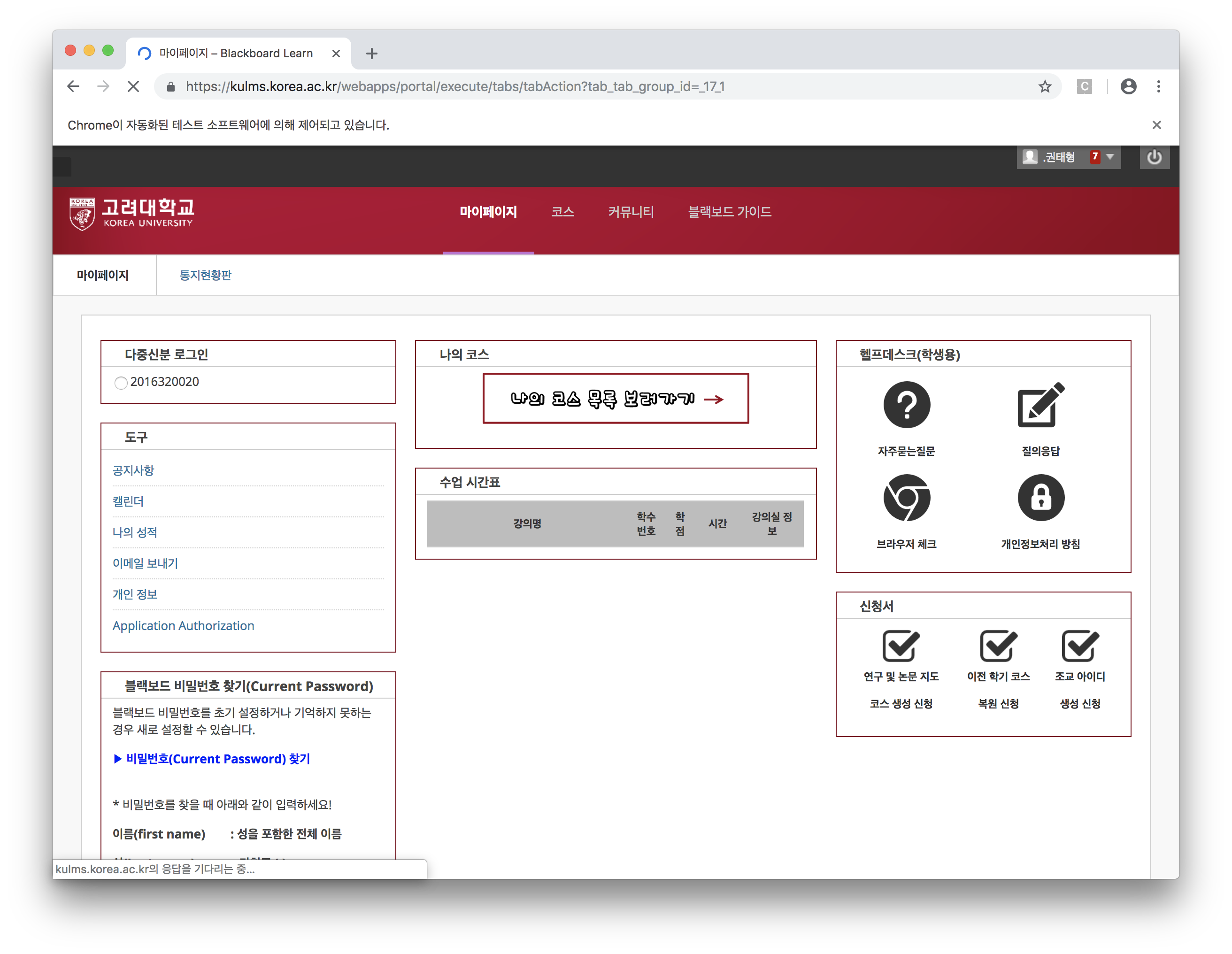
코스 과목 목록 가져오기
- 이제부터는 크롤링의 핵심 도구인
bs4를 사용합니다! - 코스로 이동하면 다음과 같이 과목 리스트가 나옵니다.
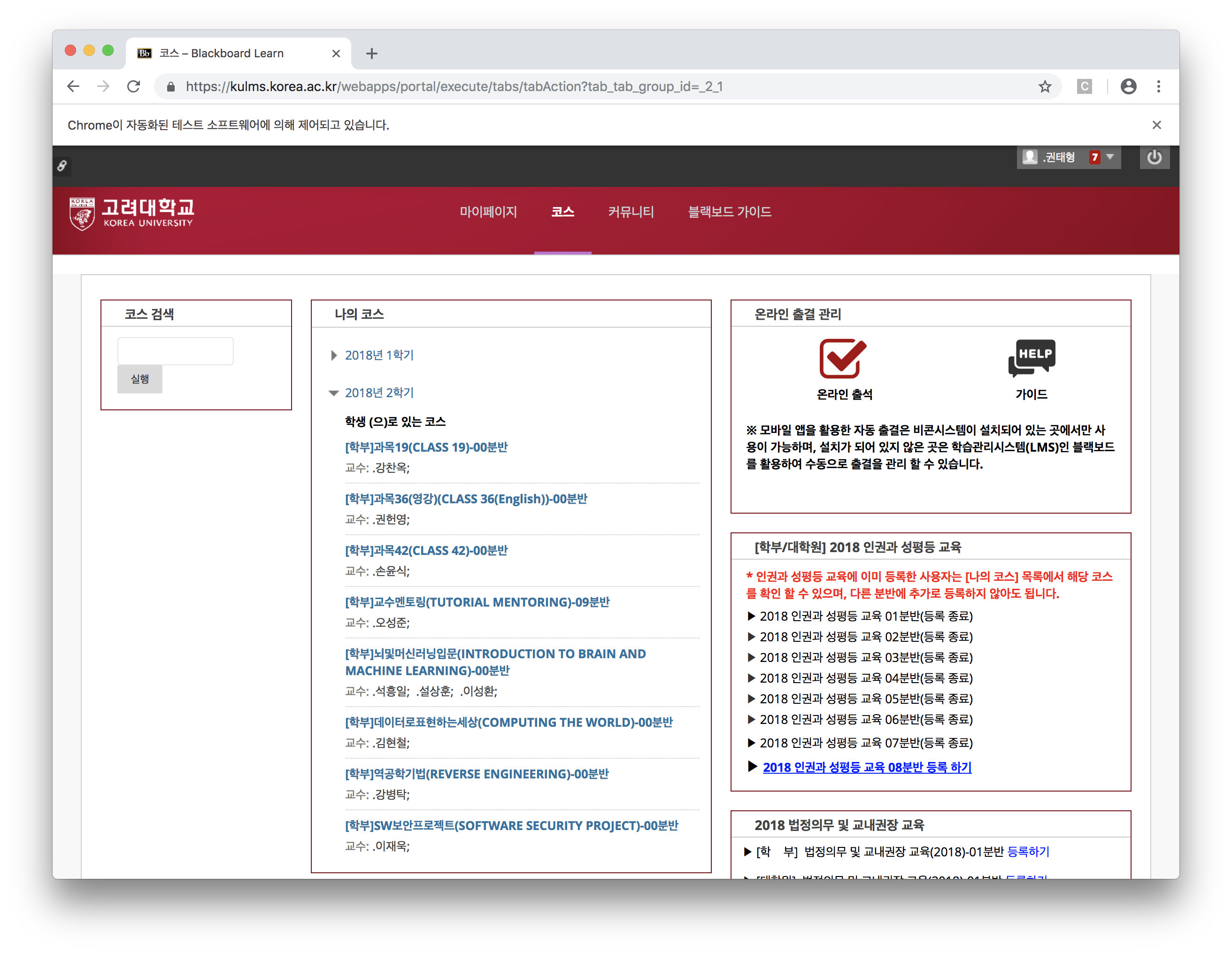
- 역시 개발자 도구로 분석해보면 다음과 같네요.
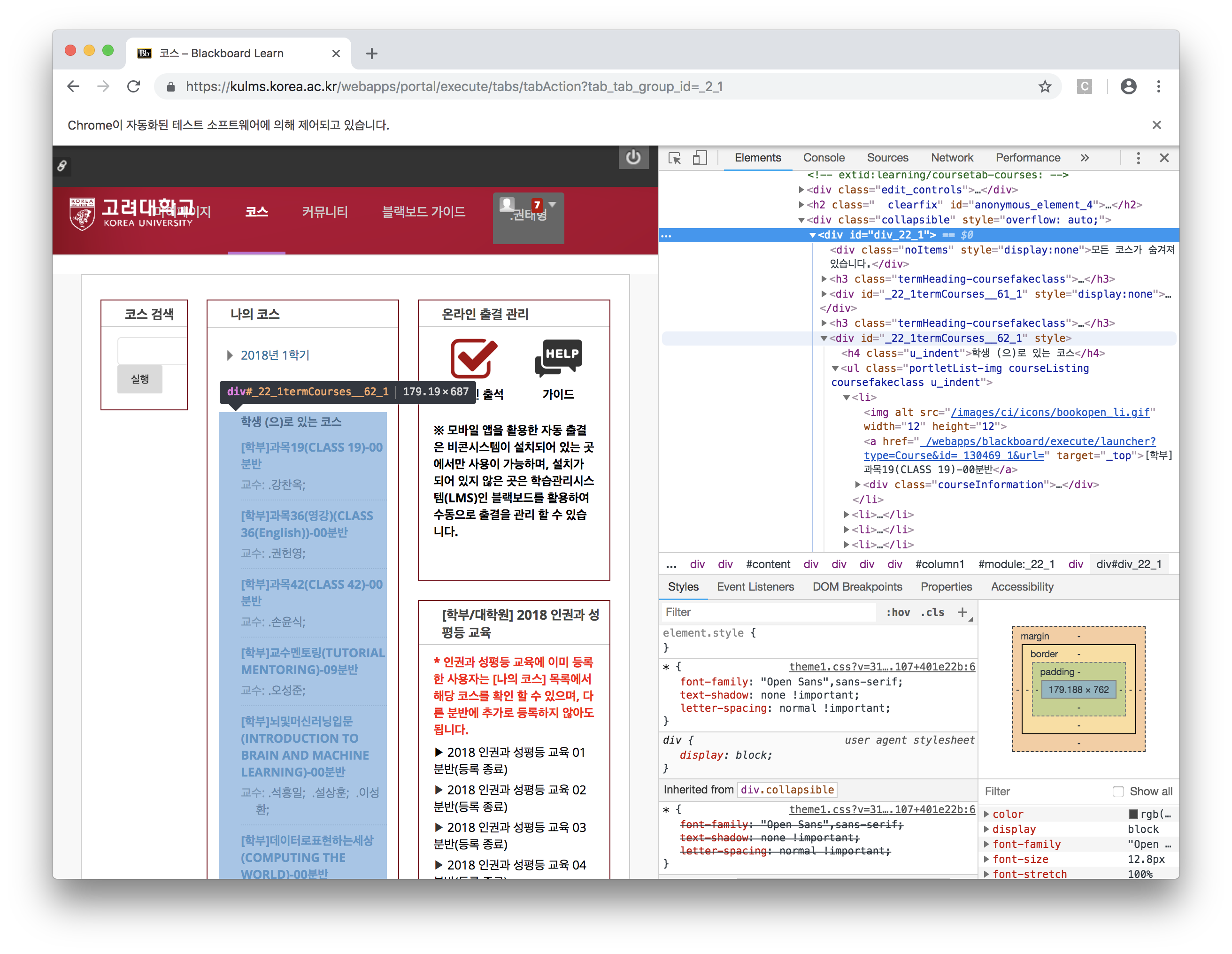
- 다음에서 볼 수 있듯 큰 div 태그 안에 작은
div id = _22_1termCourses__62_1, 그 안에ul-li-a순서대로 나와있네요. - 결국 우리가 가져오고자 하는 건 ul-li-a 에 있는 과목별 주소 목록입니다.
- 그래서 ul-li-a 의 href url을 눌러보니 다음과 같이 나오네요..!
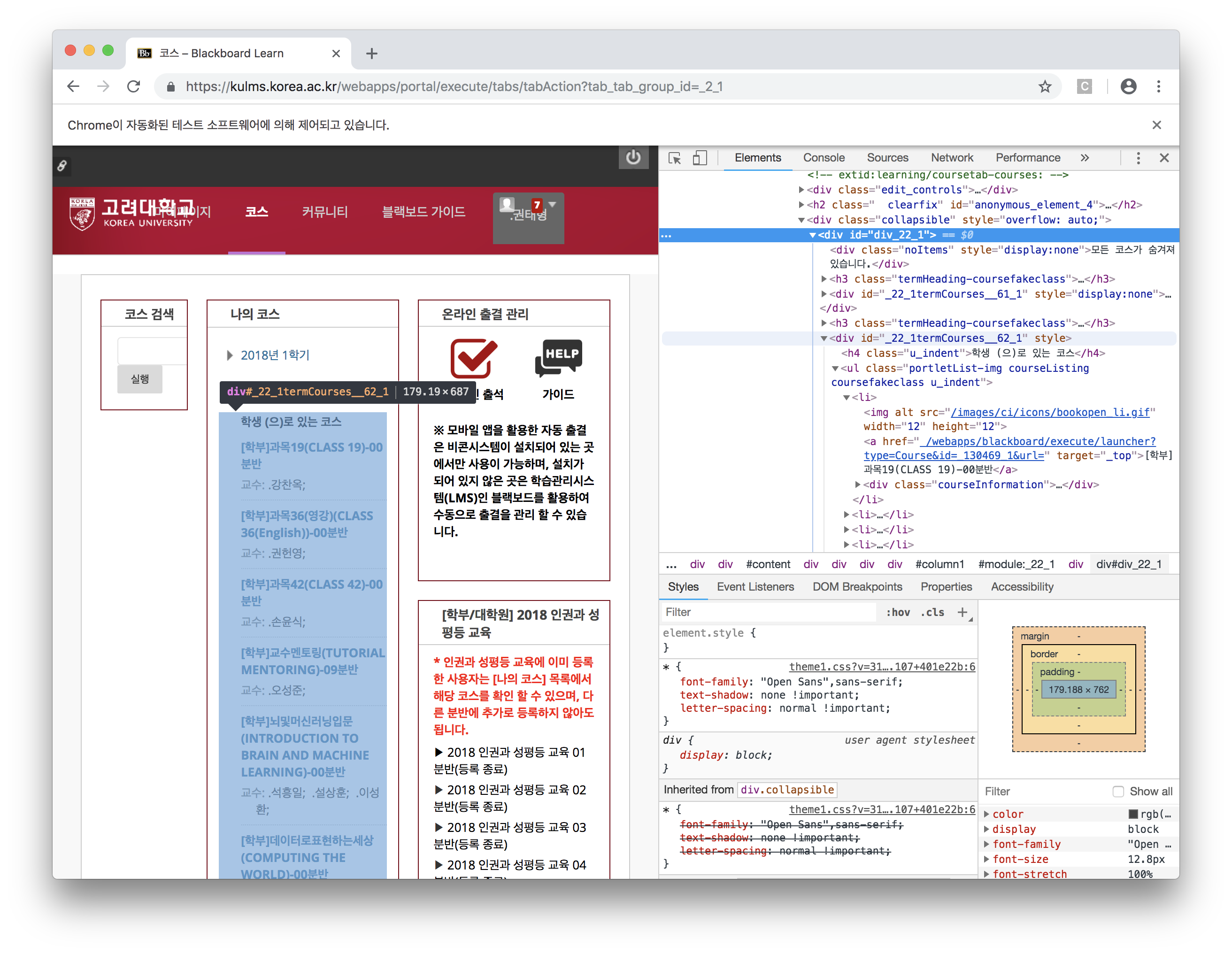
이런 경우에는 과목 url 패턴을 직접 분석해 볼 필요가 있습니다.
https://kulms.korea.ac.kr/webapps/blackboard/execute/announcement?method=search&context=course_entry&course_id=_130469_1&handle=announcements_entry이런 식으로 구성되어있는걸 확인할 수 있네요!
뒤에 &handle= 부터는 지워도 전혀 문제 없이 실행되네요! 그럼 기왕이면 간단한 URL인 다음 형태로 정해봅시다.
https://kulms.korea.ac.kr/webapps/blackboard/execute/announcement?method=search&context=course_entry&course_id=_130469_1우리는 여기서 맨 뒤의
course_id=부분이 해당 과목의 id란걸 확인할 수 있고 이것이 url에 필요한 구성요소 임을 알 수 있습니다.이 course_id는 아까 과목 리스트 ul-li-a에서 봤던 주소 안에 들어있었죠!
그럼 우리의 목표는 간단해졌습니다. ul-li-a를 모두 긁어와 그 안에 있는 course_id들을 리스트에 저장하는 일이죠.
그러기 위해서 html을 파싱해야하는데, 이때 사용하는 툴이
BeautifulSoup, BS4입니다.Selenium Driver의
.getAttribute('innerHTML')을 통해 내가 찾고자 하는 element의 HTML 값을 가져올 수 있습니다.또한 Selenium의 장점인데 이렇게 데이터를 가져오면 javascript가 실행된 이후의 페이지 데이터에 참조가 가능합니다.
이를 위해선 아래와 같이 드라이버에게 element가 load될때까지 기다려달라고 해야합니다!
…/BlackBoard-Tutorial/crawl-demo.py
1 | from bs4 import BeautifulSoup as bs |
- 그 전에 잠깐! soup.find -> element 하나를 return, soup.find_all -> element들을 list 형태로 return
- 이제 이 course_id 목록들과 앞서 정했던 각 과목별 상세 주소를 연결시켜 위의 코드에 합쳐봅시다!
…/BlackBoard-Tutorial/crawl-demo.py
1 | from bs4 import BeautifulSoup as bs |
- 좋아요! 이제 각 페이지를 탐색하는 일만 남았네요!!
각 과목별 공지/과제 페이지 URL 가져오기
- 이미지
- 위에서 만든
course_detail_list의 각 주소를 들어가보면 위와 같은 형태로 되어있을거에요. - 이제 Selenium을 시켜서, 각 주소에 한번씩 들어가서 공지와 과제란에 있는 모든 글들을 가져올겁니다.
- 그 전에 공지와 과제 URL들을 가지고 있어야겠죠?
- 마찬가지로 공지와 과제 각각 들어가서 URL이 어떻게 생겼는지 확인해볼게요.
공지:https://kulms.korea.ac.kr/webapps/blackboard/execute/announcement?method=search&context=course_entry&course_id=_130456_1
과제:https://kulms.korea.ac.kr/webapps/blackboard/content/listContent.jsp?course_id=_130456_1&content_id=_2200239_1
- 공지는 우리가 들어온 URL그대로인데, 과제는 뒤에
content_id라는 친구가 따로 붙네요? - 이 경우에는 역시 Selenium을 써서 직접 클릭해서 들어가봐야할거 같아요.
- 항상 javascript 기반의 웹 페이지는 위에서 작성했던 것처럼 해당 element가 load될때까지 기다렸다가 가져오는 걸 명심하세요!
…/BlackBoard-Tutorial/crawl-demo.py
1 | for i in course_detail_list: |
- 이제 이 코드를 조금 고치면 모든 글들을 가져올 수 있어요!
각 과목별 공지/과제 포스트 가져오기
- 이제 위 과정을 통해 모든 과목별 공지/과제 주소를 알고 있고, 심지어 과제란이 있는 페이지와 없는 페이지를 구분할 수 있어요!
- 그럼 각 페이지의 리소스를 불러와 모든 포스트들을 가져와볼게요.
…/BlackBoard-Tutorial/crawl-demo.py
1 | for i in course_detail_list: |
- 이제 실행시키면 감격스럽게도 이렇게 잘 나오네요!
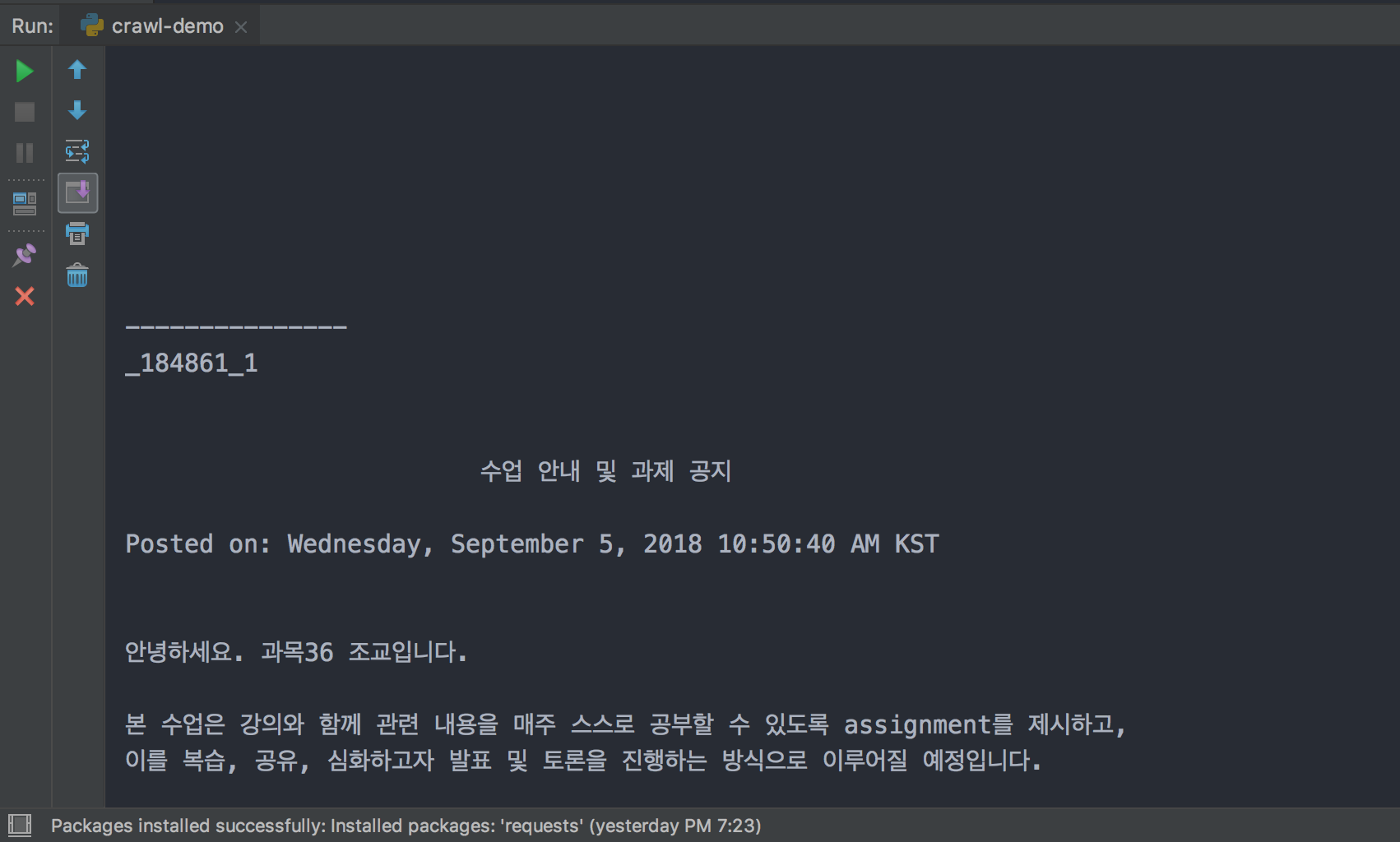
- 전체 코드는 crawl-demo.py 에서 확인하실 수 있어요!
마치며
- 이렇게 이번 시간에는 내 블랙보드의 모든 과목과 과목 별 공지/과제 데이터를 가져와서 출력하는 것까지 완료했습니다.
- 여기까지 정말 고생 많으셨어요!^^
- 만약 얘네들을 모두 메일로 보내면 매번 실행시킬 때마다 메일이 수십통씩 오겠죠?
- 그래서 이 글들을 데이터베이스에 저장하고 새로운 친구가 들어올 때마다 메일을 보낼 수 있도록
데이터베이스 연동을 해야합니다. - 다음 시간엔 데이터베이스 연동을 진행해보겠습니다.
02 블랙보드 게시글 가져와서 출력하기: Selenium 기반 크롤링 엔진 제작
https://taebbong.github.io/2019/02/11/2019-02-11-blackboard02-post/