k-최근접 이웃 알고리즘
시작하며
- 안녕하세요, TaeBbong 입니다.
- 오늘은 기계학습 알고리즘의 기초 수업의 첫 단계인 k-최근접 이웃 알고리즘, 이하 kNN 알고리즘에 대해 공부해볼겁니다.
- 기계학습 알고리즘은 앞서 설명하였듯, 두 가지의 목적성으로 크게 나뉘어집니다.
- 첫 번째는 분류, 두 번째는 회귀이지요.
- 다시 이들은 지도 학습과 비지도 학습으로 나뉘어지는데, 이 부분은 intro: 기계학습 알고리즘의 이해 에서 자세히 살펴보시면 됩니다.
- 오늘 공부할 kNN 알고리즘은 이 중 지도 학습 - 분류 알고리즘에 해당합니다.
- 즉 input data에 대한 output 결과 data를 test set 으로 넣고 특정 데이터에 대한 결과를 예측하는 것이 목표이지요.
- 또한 추정하고자 하는 것은 해당 데이터가 어느 분류에 속하는지, 분류를 알고 싶을 때 사용하게 됩니다.
- 우선 오늘의 학습은 알고리즘 개념의 이해, 알고리즘 step 별 이해, 그리고 간단한 실습 프로젝트로 진행할 예정입니다.
프로젝트 목표
- kNN 알고리즘의 원리와 개념, 필요성 및 용도를 알 수 있다.
- kNN 알고리즘을 활용한 분류기를 제작할 수 있다.
- 영화 분류기를 제작할 수 있다.
k-최근접 이웃 알고리즘이란?
- 영화를 장르별로 분류한다고 생각합시다.
- 어떤 영화가 액션영화, 로맨스영화일까요??
- 많이 간단하게 생각하면, 스킨십 장면이 많이 나오는 영화는 로맨스, 발차기나 격투 장면이 많이 나오면 액션 영화이지 않을까?
- 이와 같은 개념에서 만들어지는 알고리즘이 kNN 알고리즘입니다.
- 어떠한 기준 factor 에 대해 분류를 하게 되는 것이지요.
- 영화얘기는 생뚱 맞을 수 있으니 조금 더 이론적으로 접근합시다.
- kNN 알고리즘은 말 그대로 k개의 가장 근접한 이웃을 기반으로 분류하는 알고리즘입니다.
- 한 데이터를 기준으로 k개의 가장 근접한 이웃들의 다수가 A 분류, 소수가 B 분류라면 해당 데이터는 A 분류에 속하게 되는 것이지요.
- 즉, k개의 가장 근접한 이웃들이 해당 데이터의 분류를 결정하는, 즉 가까운 쪽에 속하게 되는 상당히 간단하고 쉬운 개념의 분류 알고리즘입니다.
- 여기서 의문점이 생길 수 있어요.
- 왜 가장 가까운 1개의 데이터에 따르지 않고 굳이 k개를 골라서 투표를 하는 번거로운 과정을 거칠까요?
- 이는 이상데이터, outlier 때문입니다.
- 데이터의 전체 경향을 볼 수 없는 상황에서 일반적이지 않은 예외스러운 데이터가 존재할 가능성이 다분하죠.
- 가장 가까운 1개의 데이터를 고를 경우 이러한 outlier에 대한 처리가 미흡할 수 있기 때문에 우리는 k개를 선택합니다.
- 이것이 k-NN의 기본적인 컨셉이죠.
kNN 알고리즘의 프로세스
- kNN 알고리즘의 프로세스는 다음과 같아요. 간단하게 정리해봅시다.
- 기존 훈련 데이터 집합(train data set)을 준비한다.
- 해당 훈련 데이터들에는 라벨(label)이 붙어 있다. 즉 각 데이터가 어떤 분류인지 정해져있다.
- 이후 라벨링이 되지 않은 새로운 데이터가 input 으로 들어온다.
- 해당 데이터를 기준으로 ‘거리’가 가장 가까운 ‘k’개의 데이터를 뽑아 그 데이터들의 분류를 확인한다.
- 이때 k개의 데이터들의 분류 중 가장 많은 쪽, 즉 다수결로 해당 데이터의 분류를 결정한다.
- 상당히 간단한 프로세스에요.
- 일반적인 기계학습 알고리즘이 갖는 훈련 집합을 기반으로 학습을 하고, 라벨링 과정을 거치지 않은 새로운 데이터의 라벨을 붙이는 과정.
- 이것이 해당 알고리즘의 전부이죠.
- 여기서 k는 임의의 정수 값으로, 알고리즘을 만드는 당신이 임의로 설정할 수 있어요!(일반적으로 20미만의 값)
- 가장 합리적인 k값을 찾는 것 또한 하나의 object 이겠네요.
- 또한 거리라는 개념을 썼는데, 거리는 여기서 유사도를 의미해요.
- 기계학습 알고리즘에서 유사도를 측정하는 방법에는 여러가지가 있고, 지금 우리가 공부하는 kNN 알고리즘은 거리를 기반으로 계산하게 됩니다.
- 이 거리를 어떻게 계산하는지는 추후에 알아봐봅시다:)
kNN 프로젝트: 영화 분류기 만들기
- 여기서는 여태 이해한 알고리즘을 직접 간단한 예제와 함께 만들어볼거에요!
- 앗, 아직 우리는 거리를 계산하는 방식을 모르는군요!
- 하지만 거리를 계산하려면 데이터가 필요하겠죠?
- 그래서 지금 실제로 데이터를 가지고 다루어봅시다.
- 데이터 이해하기 및 거리 계산에 대한 감 익히기
- 우선 다음과 같은 영화별 액션 장면 수와 스킨십 장면 수가 있다고 해봅시다.
| title | #action scene | #romance scene | type |
|---|---|---|---|
| movie 1 | 3 | 104 | 로맨스 |
| movie 2 | 2 | 100 | 로맨스 |
| movie 3 | 1 | 81 | 로맨스 |
| movie 4 | 101 | 10 | 액션 |
| movie 5 | 99 | 5 | 액션 |
| movie 6 | 98 | 2 | 액션 |
| movie ? | 18 | 90 | ? |
- 이때 거리는 다음과 같이 계산해요.
1 | d = sqrt((x1 - x2)^2 + (y1 - y2)^2) |
- 일반적인 2차원 평면 상의 거리 계산 식과 같죠?
- 당연히 여기서 x와 y는 #action scene, #romance scene을 의미합니다:)
- 그렇게 ‘movie ?’을 기준으로 계산한 거리는 다음과 같아요.
| title | distance from ? |
|---|---|
| movie 1 | 20.5 |
| movie 2 | 18.7 |
| movie 3 | 19.2 |
| movie 4 | 115.3 |
| movie 5 | 117.4 |
| movie 6 | 118.9 |
- 실제 코드 작성해보기
그럼 이제 실제 코드를 작성해볼까요!
우선 프로젝트를 생성하고, 두 개의 파이썬 파일을 만들거에요.
하나는 함수 라이브러리, 나머지 하나는 본체 코드이지요.
kNN.py
1 | from numpy import * |
좋아요! 이렇게 하면 훈련 데이터 셋을 정의, 만들어서 반환까지 하는 함수를 만든 것이죠.
분류기 함수가 정의되어있고, 알고 싶은 데이터와 기존 데이터 값, 그리고 몇 개의 이웃을 쓸지 설정합니다.
그리고 첫 블록의 코드들은 코드만 복잡하지 각 데이터 별 알고 싶은 데이터와의 거리 값을 계산하는 코드를 나눠 써놓은거에요.
반복문에 있는 건 그렇게 거리 순으로 정렬된 데이터에서 가장 위의 k개의 데이터들의 label 값들을 조사해서 이를 또 다시 dictionary에 저장하고,
이들을 또 다시 정렬, 가장 높은 표를 받은 label 값을 반환하는 것이죠.
프로그램을 실제로 실행하는 메인 부분입니다.
main.py
1 | import kNN |
- main.py를 실행시키면 다음과 같은 결과가 나와요!
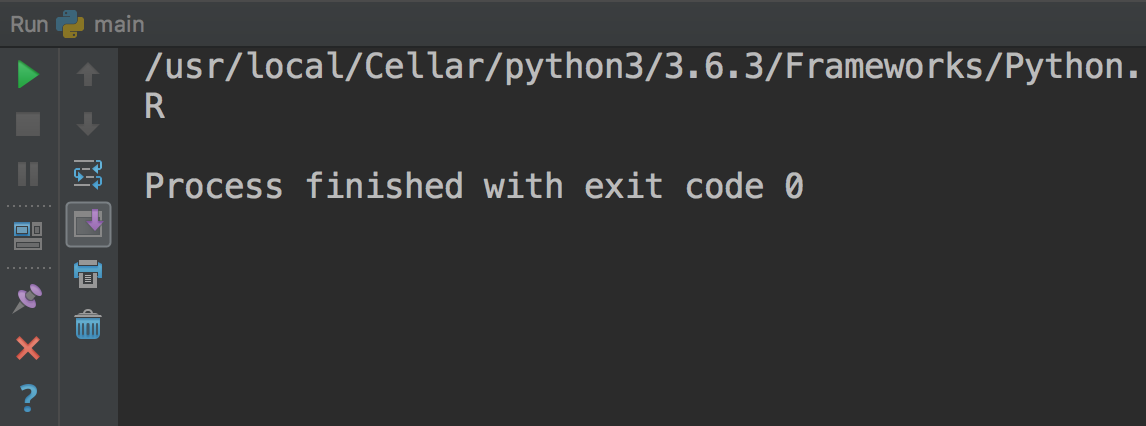 {:width=”500” height=”200”}
{:width=”500” height=”200”}
- 분류기 검사해보기
기계학습 알고리즘을 만들 때 가장 필요한 작업은 검증 작업입니다.
해당 분류기가 정말 잘 돌아가는지 확인하려면 어떻게 해야할까요?
우선은 자체적 안정성을 위해 훈련용 데이터가 많이 필요하겠죠.
또한 일부 데이터는 라벨이 없는 채로 들어가 본인의 실제 라벨과 분류기에서 판단한 라벨이 동일한지도 확인해야겠어요.
이 비율을 뭐 적당히 훈련 8: 테스트 2 로 정해봅시다.
이와 같이 전체 훈련용 데이터 집합에서 일부를 테스트 데이터로 따로 빼서 검증하고, 그러한 일부를 무작위로 수차례 뽑아서 테스트를 진행하는 것을 ‘교차 검증’ Cross Validation 이라고 합니다.
여기서는 이를 자세히 다루지는 않겠지만, 조만간 포스트에서 이를 코드로까지 구현해볼거에요.
대신 우리는 그럼 간단하게 수차례 뽑지 않고 한 번만 뽑아서 테스트를 해볼게요.
다시 코드를 작성해볼까요?
kNN.py
1 | def validTest(): |
- main.py
1 | kNN.validTest() |
- 결과는 어떻게 나왔나요?
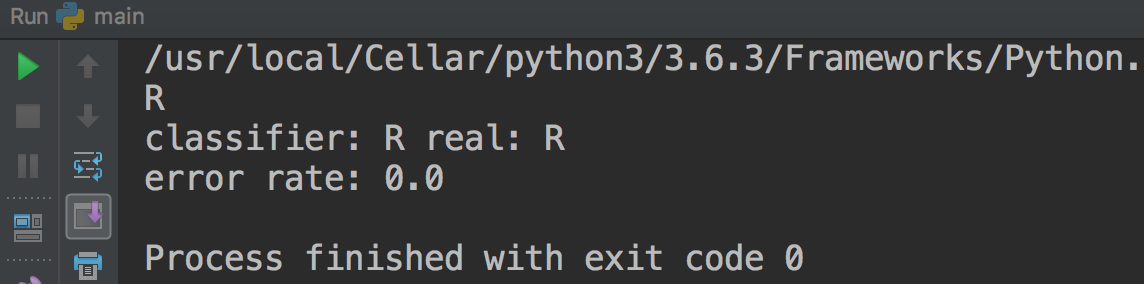 {:width=”500” height=”100”}
{:width=”500” height=”100”}
- 현재 데이터셋이 6개 밖에 없어 0.2 비율로 하면 1개 뿐이라 결과가 잘 나온 것처럼 보이네요.
- 이처럼 검증 과정을 거치기 위해선 데이터가 꽤 필요하답니다:)
번외: scikit-learn을 써보자.
우리는 여태 꽤 많은 코드를 작성했어요.
거리계산부터 정렬, 선별, 투표, 결정 그리고 마지막 검증까지.
이러한 kNN 알고리즘은 이 모델이 대부분이에요.
즉 분류기는 변하지 않는다는 말이죠.
그렇다면 이 코드를 매번 작성 해야할까요?
다행스럽게도, 이와 같은 알고리즘들을 라이브러리 형태로 만들어놓은 오픈 소스가 있습니다.
바로 scikit-learn이지요!
scikit-learn에는 오늘 배운 kNN 알고리즘 뿐만 아니라 여러 앞으로 배울 기계학습 알고리즘들이 존재합니다.
오늘 그러면 간단하게 이를 사용해보도록 해요:) 코드가 대폭 줄어드는 경험을 할 것입니다.
일단 scikit-learn을 사용하려면 설치를 해야해요.
터미널을 켜봅시다.
1 | sudo pip install scikit-learn |
- 간단하게 설치를 마쳐주고, 코드를 작성해봅시다:)
1 | from sklearn.neighbors import KNeighborsClassifier # import kNN from scikit learn |
- 결과는 다음과 같아요.
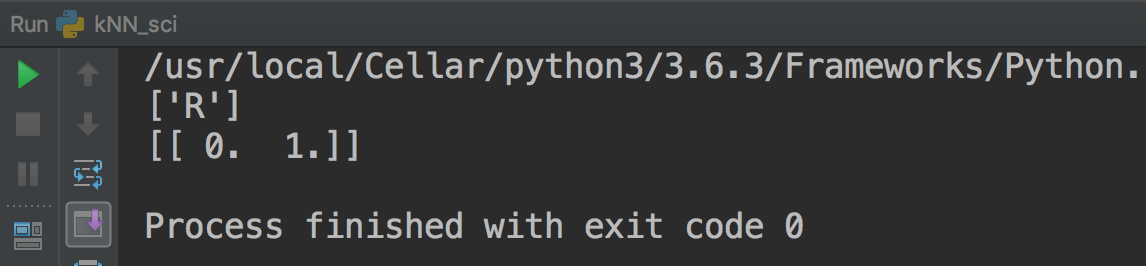 {:width=”500” height=”100”}
{:width=”500” height=”100”}
- 정말 억울할 정도로 간단하죠?
- 이처럼 scikit-learn을 활용하면 코드를 훨씬 쉽게 쓸 수 있어요!
- 공부하는 차원에서는 일단 많이 쓰지는 않을게요:)
마치며
- 오늘 살펴본 알고리즘, 어렵지 않았죠?
- 분류기 예제 문제 자체가 상당히 간단하지만, 이게 다에요:)
- (사실 NN regression, unsupervised NN, kDTree처럼 아직 못한게 많지만)
- 여기에 데이터를 형태에 따라 수치형으로 가공하고, 정규화를 시키고 하는 데이터 처리 기법만 다를 뿐 기본 베이스 알고리즘은 똑같답니다.
- 물론 이제 새로 테스트 해본 데이터를 훈련 데이터 집합에 추가하여 점점 똑똑해지는 방식을 취할 수 있지만 이는 굳이 여기서 다루진 않을게요.(append만 하면 되니..)
- 여기까지 k-NN 알고리즘이었습니다:)
- 기계학습의 기초 포스팅은 다음 도서를 교재로 사용하고,
 {:width=”50” height=”100”}
{:width=”50” height=”100”} - 다음 API Document를 참고합니다.
- scikit-learn